
5 characteristics of data quality - How good is your data?
20 Dec 2021

Data can create a competitive advantage for your business. More specifically, good data can provide you with a rich understanding of your business, customers or market position, which in turn can inform your next course of action. In a similar vein, bad data can have disastrous outcomes as a result of misleading insight or ill-advised business strategies.
According to research conducted by Gartner, poor data is costing organisations an average of $12.9 million a year. Gartner also found that nearly 60% of companies surveyed couldn’t quantify the cost of bad data to their businesses because they don’t measure it in the first place.
We are often engaged by organisations to provide an assessment of their data quality as well as recommendations on how it can be improved or leveraged based on industry best practice. Lets dive into the top 5 characteristics we use to assess data quality for our clients.
1. Data Accuracy & Validity
Data cleaning and manipulation are pivotal for ensuring the accuracy and validity of data used by analysts and data scientists. Beyond addressing format issues, spelling mistakes, and duplicates, it’s crucial to implement thorough validation checks. This includes cross-referencing data against external sources or business rules to confirm its accuracy. Employing statistical methods and data profiling techniques enhances overall quality and trustworthiness.
Data accuracy and validity are measured by calculating the percentage of records passing automated validation checks against predefined business rules and external reference data.
2. Data Uniqueness
Data uniqueness plays a pivotal role in preventing redundancy and ensuring precision in datasets. To achieve this, consider implementing unique identifiers or keys within your data model. Additionally, leverage advanced algorithms or fuzzy matching techniques to identify and handle duplicate records. Regularly audit and cleanse your database to maintain a high level of uniqueness, reducing the risk of errors caused by duplicated information.
Data uniqueness is quantified by assessing the ratio of unique records to the total dataset, using identifiers or keys, and identifying and resolving duplicates through advanced matching algorithms.
3. Data Completeness and Consistency
Measuring data completeness involves more than identifying missing values. It requires a nuanced understanding of the context and implications of missing data. Implement strategies such as imputation techniques to fill in missing values responsibly. For consistency, establish data quality standards and enforce them throughout your data processing pipeline.
Data completeness is measured by evaluating the percentage of missing values within key attributes, while consistency is assessed by quantifying adherence to standardised formats, units of measurement, and naming conventions.
4. Data Timeliness and Availability
Data timeliness assesses whether the information is available when it is required. To ensure data timeliness, consider incorporating real-time data streaming or automated synchronisation processes. Implement clear data refresh intervals to keep information up-to-date and relevant.
Beyond being current, data availability assesses the accessibility and readiness of information at any given moment. An effective data infrastructure ensures that relevant data is consistently accessible to users, preventing delays in decision-making processes. Combining both timeliness and availability ensures that your data remains a reliable and responsive asset for informed decision-making.
Data timeliness is measured by analysing the time lag between data updates and event occurrences, while availability is assessed by calculating system uptime and response times during critical decision-making periods.
5. Data Integrity
Maintaining data integrity is a continuous process involving comprehensive checks and controls. Implement referential integrity constraints within your database to ensure relationships between tables are maintained. Regularly audit data for anomalies or inconsistencies and employ encryption techniques to safeguard against unauthorised alterations.
Data integrity is measured through the implementation of referential integrity checks, and periodic audits to detect and rectify inconsistencies and unauthorised alterations.
A case study: customer address cleaning
A common dataset we work with involves customer addresses. Here is a basic example, we can see the address components are not in the right place and inconsistencies in date formats. There are also multiple addresses for the same customer.
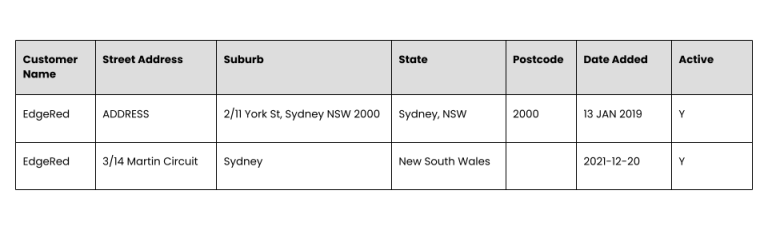
This is the result after standardising and cleaning the data.
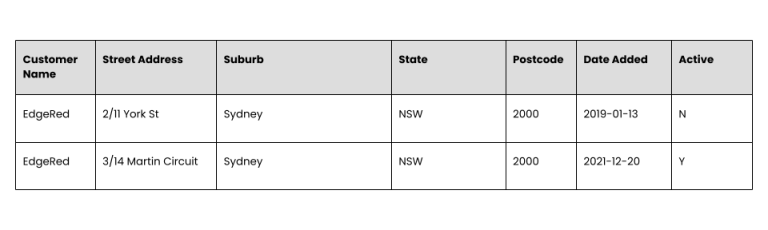
The address is now clean, but is it accurate? We ran an address validation against a list of all Australian addresses and found that the address above does not exist – in fact, the street name was misspelt.
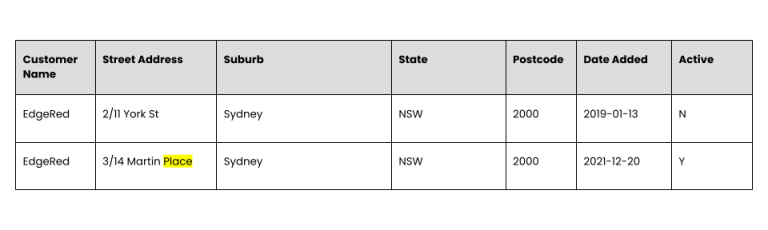
We completed a once-off assessment and data cleanup for the client, however it’s likely that there is a structural problem which means that unless that’s fixed bad data will reappear eventually, and our client will have to clean the data again and again.
After conducting an investigation, we introduced implemented a few additional best practices,
Target the data capture process to prevent poor data at entry – this was through integration with an address validation APIs
Training session to relevant team (including marketing) to raise awareness of the importance of clean data and set standards for how data should be entered
Clear identification of data owners / data stewards whose role is to monitor and champion good data quality (and escalate any issues)
Establish a set of benchmarks that can be used to measure data quality and regularly monitor the data to ensure that it meets these standards
Following these best practices will help our client preserve good quality data for years into the future and help them get the best outcomes from their data. Read about how we’ve integrated Great Expectations, dbt and Kada to define and monitor data quality for our clients.
About EdgeRed
EdgeRed is an Australian boutique consultancy specialising in data and analytics. We draw value and insights through data science and artificial intelligence to help companies make faster and smarter decisions.
Subscribe to our newsletter to receive our latest data analysis and reports directly to your inbox.



